In the last post we saw how systems powered by AI shift harm between population segments, and that there are some practical, physical methods that can be employed to shift those harms back. These were called Protective Optimization Technologies (POTs) because they are designed to protect the people who employ them from harms caused specifically by a system optimizing for a particular metric. These techniques can be thought of as counteracting the original intention of the technology and thus can also be thought of as "subversive" AI.
The cases presented in the last blog post had to do with surveillance enabled by computer vision, discriminatory loan terms enabled by algorithmic risk assessment, and traffic congestion encouraged by route optimizers. There is another case not covered by the original paper that has gained a lot of interest in the last two years as generative AI models have become increasingly capable. This use cause is intellectual property.
IP might sound a bit lawyery and technical but there are two important and simple things to know. Every creative act by a person is protected by copyright, with limited exemptions for fair use (e.g. commentary, parody). Every creative act by a machine has no copyright protections at all, at least according to the United States, at least for now.
So what happens if you train a generative image model on an artist's work, such that it reproduces that work in its entirety? The output from the artist is protected by copyright, and the output from the model is not, but they are visually identical.

Can the artist extract royalties from the model for reproduction? Or can the artist forbid any model to be trained on their artwork?
These two questions are currently working their way through the court system. But in the mean time, there are artists whose work is being copied or mimicked. And not just famous ones like van Gogh either -- it's trivial to fine tune an image generation model to reproduce work in the style of any artist who has posted a large corpus of their work online. Is it possible for them to protect their intellectual property before the courts can act?
A team at the University of Chicago tried to figure out how to make this work well in practice. The two methods they have distributed both rely on data poisoning. The basic idea behind data poisoning is this -- if I control a small fraction of the data used to train someone else's model, can I cause their model to fail by adding modifications to the data I own?
If you would like to learn more about data poisoning, we have a series of blog posts about it, and you can see them all here: posts tagged with "data poisoning".
Data poisoning is particularly attractive for this task for two reasons. First, unlike most threat modeling scenarios, the artists themselves are the ones posting the images online, and data scraping algorithms only interact with the digital versions. This allows them to add perturbations in the pixel values of the image that might not survive the noisy process of camera capture and preprocessing that is common in most threat scenarios.
The second is that data poisoning has been previously shown to be effective with a relatively small number of poisoned examples. If you think about the total number of images in a modern dataset (every image on the internet), the fraction that you personally control as the artist will be relatively small. Well crafted attacks are often successful in achieving their objective with 1% or fewer poisoned examples, which is helpful in this case.
The Chicago team's first attempt at artist protection was against an image generation method known as style transfer.1 The basic idea is to ask for content keywords (like "a dog") but in a particular style (like "by van Gogh"). For very famous artists, this can be done by combining these two things ("a dog by van Gogh") as the input to the image generation model. Less famous artists are unlikely to be in the training dataset at all, or they work may have shown up so infrequently that the model has not learned their particular style. In these cases, existing models (like stable diffusion) can be fine-tuned to re-create works in that particular style.
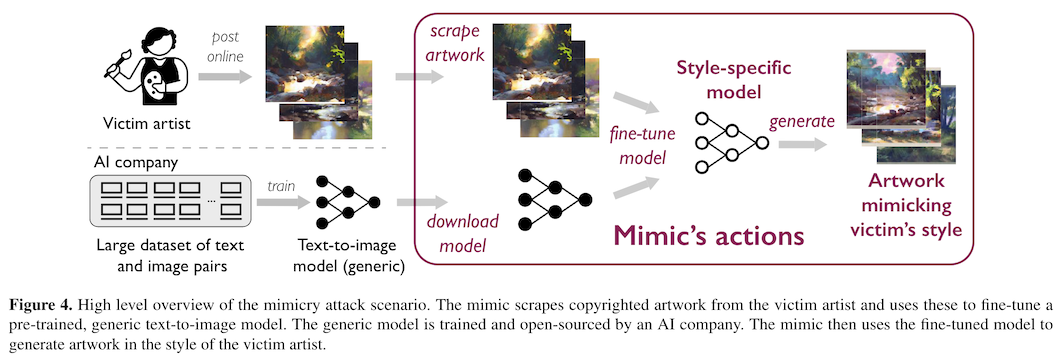
For the artists to protect themselves against this kind of mimicry, they need a method to make the advertising of their work that they post online unhelpful -- or actively harmful -- for models fine-trained on them. They need to attack the style transfer specifically.
To achieve this, the authors construct a per-artist dataset of negative examples. They use an existing computer vision model to compute the condensed feature representation of an artwork -- not a prediction, just the low-dimensional internal representation -- and then look for known image styles that are medium-far from that internal representation. So, for example, if you were trying to protect the artwork "Starry Night" you might choose the style of an artist like Picasso.
The next step is to use an existing style transfer model to create a version of "Starry Night", but in the style of Monet. You now have two images -- the original artwork that you want to protect, and a style transferred version.
They then perform an image update step, similar to iterative projected gradient descent for adversarial attacks. In their case though, they are not trying to maximize a classification loss because the classification is both not available and also doesn't really matter. What they are trying to do is maximize the similarity of the features output by their pre-trained model for the artwork and the image-but-in-a-different-style. At the same time, they aim to minimizing the perceptual difference between the original image and the perturbed one. Usually this is done with a simple L2 norm on the pixels -- these authors use a more complicated method which we might write a blog post about at some point.

You end up with an image that looks perceptually similar to someone, say, shopping for online art or browsing Instagram, which is the intended audience. But to a style transfer model it will have tiny changes that make it look like a cubist painting instead of an impressionist one.
This might feel nonsensical if you are not familiar with computer vision, but the basic explanation is that computer vision models pay a lot of attention to details that are either beneath the level of human perception or irrelevant to the actual task. Two well-known papers about this are
- A. Ilyas, S. Santurkar, D. Tsipras, L. Engstrom, B. Tran, and A. Madry, “Adversarial Examples Are Not Bugs, They Are Features,” Available: http://arxiv.org/abs/1905.02175
- D. Hendrycks, K. Zhao, S. Basart, J. Steinhardt, and D. Song, “Natural Adversarial Examples,” Available: http://arxiv.org/abs/1907.07174
The end result is that fine-tuning models will pay attention to the imperceptible details, and learn to generate cubist artwork whenever someone tries to copy Starry Night.
So how well does this work? According to the authors, quite well. In their analysis, 97% of the time, style transfer failed to copy an artist's actual style, and re-created a different style instead.
However, as we have seen before, adversarial inputs (like poisoned data) can be brittle, and in this case someone found a workaround for the Glaze protection algorithm in just two days: Glaze owned by downscaling. Another research team, this one at Maryland, has argued that Glaze is also susceptible to JPEG compression and that the original authors did not test this as extensively as they should have: JPEG Compressed Images Can Bypass Protections Against AI Editing, see also What your model really needs is more JPEG!
As the authors note, attacks and defenses exist in a kind of arms race, and no method is guaranteed to be fool proof or long-lasting.
About a year later the Chicago team tried another approach.2 This time, instead of attacking fine-tuned models, they would attack the first scenario where the artist or style is mentioned directly in the prompt. You might think that this would be much harder, since the model you are trying to poison has been trained on every image on the internet, but the authors find that the attack strength varies with prompt frequency, not with total dataset size. In other words, the more specific the prompt is (e.g. mentions the artist's actual name) the smaller the amount of poisoned data you need. In that case in particular, the authors claim to need as little as 100 poisoned examples from an artist to hide their specific style.
This time, we're not really hiding an individual artist's style though. In Nightshade, the authors propose to attack whole concepts, no matter which artist uses it. There is one case where this is is particular to defending one artist (e.g. in the style of van Gogh), but there is another case where this is common to many artists (e.g. in the style of fauvism).
The approach is similar to Glaze but with one crucial difference. Recall that in Glaze, the authors were trying to protect an individual artist from style transfer specifically. In Nightshade, the authors are trying to remove the ability of a model to learn individual concepts during the pretraining step. So instead of looking for a style that is somewhat different than an individual artist, what we need now is a concept that is somewhat different.
This is a nontrivial task. If you are trying to take the concept of a dog and poison it with the concept of a cat, how should you go about it? The authors decide that they want the training data to look realistic, so they still end up building a corpus of images (this time by concept, not style). But! Now the transfer target is fake.

The authors take a pre-existing image generation model and ask it to make prototypical images for a particular concept. They then take a real image from a different concept and perturb it in a similar manner as before so that the perceptual differences are minimal but the model feature representation of the real image becomes closely aligned with the generated concept image. They inject these into your dataset (e.g. the internet) with labels that match the real image, which a machine learning model will learn to associate with features from the generated image.
This is clever! By using generated images, the authors are ensuring that they are attacking the kinds of features most preferred by the generative model. And according to their self-reported metrics, Nightshade is successful and robust, and can even help artists who are not using the attack avoid these kind of style-matching prompts.

So what's the catch? Well, two things. First, preventing someone from copying your work is a very different thing than preventing them from producing any desired outputs at all. The Computer Fraud and Abuse Act has a specific provision against causing a global disruption of someone else's computer system, so this attack carries a legal risk that Glaze does not. See "Is it illegal to hack a machine learning model?" for more details.
Finally, this attack involves taking a real image and shifting its low dimensional feature space toward an image generated by an existing model. If Nightshade were successful in poisoning the popular image generators, it would impact the tool's ability to generate defenses in the future. This is important because the open source models used by Nightshade are typically trained on open source datasets collected from the web, but this is not true of all models, and especially not proprietary ones.
Is this interesting?
-
S. Shan, J. Cryan, E. Wenger, H. Zheng, R. Hanocka, and B. Y. Zhao, “Glaze: Protecting Artists from Style Mimicry by Text-to-Image Models”.
-
S. Shan, W. Ding, J. Passananti, H. Zheng, and B. Y. Zhao, “Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models.” Available: http://arxiv.org/abs/2310.13828