It's trite to note how pervasive AI systems are becoming but that doesn't make it less true. Some of these systems -- like AI chatbots -- are highly visible and a common part of the public discourse, which has spurred some notable AI pioneers to publicly denounce them. However most AI powered systems are developed away from the public eye and can have immediate and serious harm, as many researchers have pointed out.
Maybe you saw this recent 404 Media story about the growing trend of police departments linking privately owned security cameras into regional surveillance hubs. There was also quite a bit of press coverage over the years about Ring allowing law enforcement to access camera footage without a warrant (a practice that was stopped only recently).
As these articles note, AI (like many things) is a technology that can be used for help or for harm. In the 404 Media writeup Cox presents arguments about the benefits for public safety, as in a more rapid response to active shooters. Other communities in that story are worried about the potential for unwarranted harassment of their citizens -- a timely concern, seeing as the FTC just banned Rite Aid from using facial recognition in its stores for that reason.
But let's imagine that there is some company or organization who would like to employ an AI powered system, but only in a way that does not cause harm. Will they succeed?
It might feel intuitive that the answer is yes or at least maybe, but a 2020 paper titled "Protective Optimization Technologies" argues that this is not possible in any practical sense.1 The reasons why are a bit complex, so first we'll need a bit of framing around the question.
In particular, we will need to divide the problem domain into two pieces. First, there is an AI system that is designed to optimize certain objectives based on a simplified view of the world (the authors call this the requirements of the program being derived from domain assumptions, referencing the work of Michael A Jackson). Second, that system is deployed in the world where it acts based on inputs (the authors call this the application domain and the phenomenon, respectively).
Much of the current academic work on AI systems is focused on the first piece specifically, under the name algorithmic fairness. So, for example, if a benign organization has deployed a facial recognition system, they may want to ensure that its false positive rate is not different across genders or ethnicities. This kind of fairness can be part of an objective that the system optimizes when it is designed.
However, fairness alone does not guarantee that the system will not cause harm, because of that second part, where it gets deployed into a world. This distinction between the design of a system and the operation of that system is similar to the separation between security and safety in information security.2 To wit, a system operating as designed (secure) can still behave in unexpected ways (unsafe).
One reason this might happen is a mismatch between the deployment environment (real world) and the model of that environment used to design the application. A simple example of this is designing and testing phones in the United States, but selling them worldwide. If users in other countries look different, then computer vision models on the phone may fail to function properly. There was an example of this in 2017 when a Chinese woman reported that unrelated adults were able to unlock her iPhone using FaceID.
A second reason this might happen is difficulty in measuring utilities, which is a common problem for marketplace applications. In these systems, information about local values and preferences gets surfaced by the market in the form of prices. However, this information only includes active participants in that market and so does not account for harms that extend outside their userbase. So, for example, the prices for short term rentals on AirBnB do not reflect the cost borne by local residents in the form of increased rents.
To address this second case, the authors propose the development of technologies that allow people to move the behavior of AI systems closer to their own preferences. And, importantly, because these technologies are used by the society where the AI system is deployed, it doesn't require that the owner of the AI system is trying to make it fair or safe.
So what does such a technology look like? The instantiations are all very different but they share the step of putting something physical into the world that affects the inputs to an AI system. The authors present two case studies.
The first is local traffic congestion caused by driver routing programs. In particular, when the average highway traffic speed drops below a critical value, these algorithms will divert non-local traffic onto local roads, which causes harm for non-users of this system in the form of congestion and pollution. By slowing traffic specifically on roads used by these routing algorithms to circumvent slow highway speeds, it's possible to decrease the critical value and keep more non-local traffic on the highway. The physical changes could be reduced speed limits, lane reductions, lane narrowing, or added traffic lights.
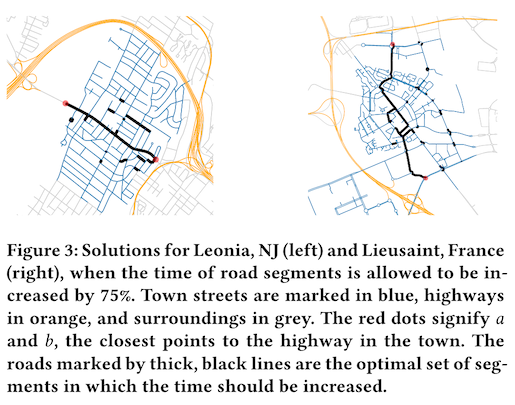
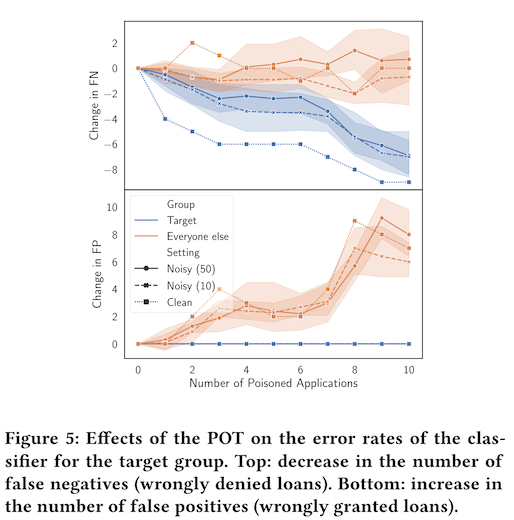
The second use case is loan approval, and in this example the authors focus specifically on models that predict likelihood to repay, which is a critical factor in securing a bank loan. The harm here is that someone who deserves a bank loan might not get one, because the model has learned some spurious relationship between non-relevant attributes and credit risk. The authors show that a data poisoning attack -- where additional loan records are added to the training data -- is capable of reducing false negatives for otherwise worthy applicants.
A third use case comes from a different paper called "Subversive AI" about the usefulness of adversarial machine learning to human-centered algorithm development.3 The harm being considered in this paper is harm from surveillance, in particular the use of computer vision to identify and track protestors, religious and/or ethnic minorities, and LGBTQ+ people. The protective technology is visual obfuscation like adversarial patches that cause the automated system to fail at detecting a particular person or thing (i.e. an evasion attack).

Importantly, these technologies do not reduce harm in a global sense, but instead shift it from one place to another. In the first case study, adding impediments to speed on local roads will increase travel times for residents of the town, saying nothing of the decrease in utility for the highway drivers. In the second case study, the data poisoning attack decreased the chance that a credit-worthy applicant would get unfairly rejected by the system, but this came with the tradeoff of approving loans for more people who would not be able to repay. The negative consequences of this then either shift to the bank, which sees a monetary loss, or to future loan applicants who see increased interest rates.
There is the obvious concern then that by protecting yourself you may be harming someone else. There is a second-order effect on these methods however that involves the owner of the AI system. Even if they want to have a fair system, they are likely to react negatively to the deployment of technologies that make the system itself less effective at functioning. In this sense, the deployment of things like adversarial patches or poisoned loan applications sets up an adversarial game with a partner that could have been cooperative, and thus carries the risk of a lower utility for everyone involved.4
In the worst case, these technologies can create arms races between those who want to use a protective technology and those who want to maintain the optimality of their AI system. Because the people who need protection are those with the least ability to create these technologies on their own (e.g. because they are not in positions of wealth or power), they are also not likely to win that arms race. We are already seeing this with Glaze and Nighshade, but that discussion will have to wait for a future blog post.
Is this interesting?
-
1. B. Kulynych, R. Overdorf, C. Troncoso, and S. Gürses, “POTs: Protective Optimization Technologies,” Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 177–188, Jan. 2020, doi: 10.1145/3351095.3372853.
-
2. H. Khlaaf, “Toward Comprehensive Risk Assessments and Assurance of AI-Based Systems,” 2023.
-
3. S. Das, “Subversive AI: Resisting automated algorithmic surveillance with human-centered adversarial machine learning,” p. 4.
-
4. See e.g. the Nash equilibrium