In the last three posts, we've looked at different ways to defend an image classification algorithm against a "classic" adversarial attack -- a small perturbation added to the image that causes a machine learning model to misclassify it, but is not detectable to a human. The options we've seen so far are the following:
- Train the model itself to be robust to adversarial inputs
- Find a way to remove the adversarial perturbation from the image before giving it to your model
- Detect that an input image contains an adversarial attack, and refuse to give it to your model
But let's say your motivation is a little different. What if you already knew that you had a model under attack? E.g. maybe you are using that steganalysis method from this article and you have a few input images that you know are malicious. Can you tell how they were made?
There are two reasons in particular that you might want to know how someone is generating an attack against your deployed model. First, Carlini established a while ago that defenses against one kind of attack can almost always be bypassed by a different kind of attack.1 For a really robust end-to-end pipeline, you might want something that looks like:
detect attack -> classify attack -> attack-specific denoiser -> regular classifier
or
detect attack -> classify attack -> attack-specific robust classifier
We are assuming for the sake of this example that you can reliably detect an attack, which remains an open research question.
You might also want to know if the attack is adaptive, that is, is the attacker watching your system respond in real time and modifying the attack that they are using. If they are, it might be more cost effective to locate the origin of the attack (e.g. IP addresses, user accounts) and control it at the network layer or the application layer instead of trying to mitigate the attack at the inference layer.
The second motivation behind detecting attack methodology has to do with threat intelligence. If you know that someone is sending a few malicious images to your network that they generated with some off-the-shelf implementation from GitHub, then you may not care to create an incidence report or investigate further. On the other hand, if your service is getting flooded with attacks that only weakly correspond to known vectors this indicates that some person or group of people has put a lot of effort into causing your model to misbehave. And that could be cause for great alarm.
Most of us are not in a position to value this second reason, but if you are, say, the US Department of Defense, or anyone else whose threat model includes nation-states with literal hacker army divisions, this kind of information is critical to your mitigation response. So a team at Embedded Intelligence decided to do a proof of concept about how feasible this really is. Their paper is called "Reverse engineering adversarial attacks with fingerprints from adversarial examples".2
Let's start with the bad news. Again, we're assuming that you already know that your model is under attack. If you try to build a classifier to tell which kind of attack you are facing, given only attacked input images, your average accuracy accross 4 attack families and 17 total attack instances is just around 50%. Now this is better than chance, but not enough to reliably tell the difference between two very different attack families, like FGSM and PGD -- and definitely not good enough to find the closest known attack to an unknown vector. If you were hoping to use this method for threat intelligence, this accuracy won't be enough.
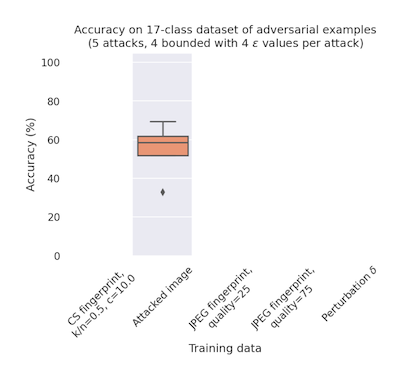
So Nicholson and Emanuel set up an experiment, where they make a training dataset by attacking Imagenette using FGSM, PGD, a black box method we haven't talked about in this blog called square attack, and the original adversarial patch attack, which we wrote about in Fooling AI in real life with adversarial patches. The test set is the original Imagenette test set, with the same attacks.
As an initial approach, the authors relax the problem to one where the adversarial perturbation is transparent. That is to say, they are pretending that there is a genie inside their pipeline that can separate the attack from the original image. This separates the problem of detection from the problem of classification and serves to make the exploratory work more tractable.
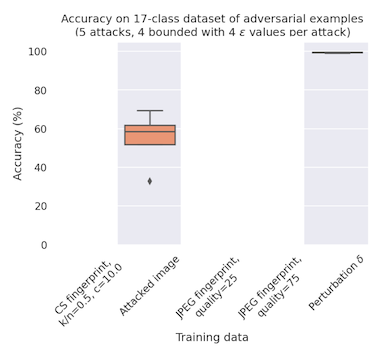
If you can see with 100% accuracy the true adversarial perturbation, you can tell with close to 100% accuracy which attack it came from. This is an important first result, because it demonstrates that classifying attack families is trivial in a white box setting. The real challenge in this particular problem is how to recover a good estimation of the attack perturbation itself.
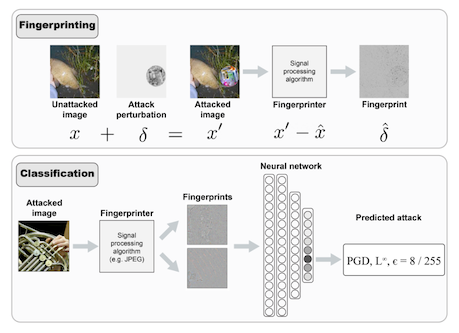
The second step Nicholson and Emanuel take is applying two different image cleansing methods to the inputs, and using the difference between the original input and the clean input to represent the attack. This representation is then fed to a classifier, which attempts to classify the attack methodology.
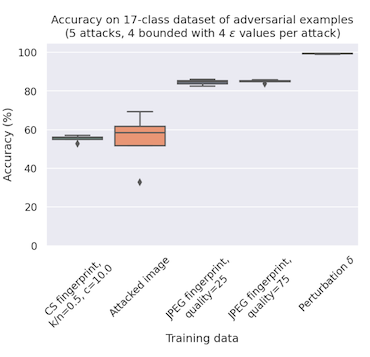
The first method is really no better trying to classify the input images directly, but the second one...
The authors use the difference between JPEG compression and an input image to represent an estimate of the attack perturbation, and this increases the classification accuracy from 50% to 85%.
Now this is obviously not as good as the 99% accuracy on the true perturbation, but JPEG compression is a fast and cheap method not at all tuned for denoising adversarial attacks. You could imagine a compression algorithm much more robust to adversarial inputs -- like, say, a denoising VAE -- would do much better. But knowing where the challenge is and where the development effort should go is an important question to answer.
Where to from here? Better fingerprinting is the obvious next step, but there are several lines of inquiry that could be initiated even using the white box results. With enough examples, you could build a sort of evolutionary tree of attack methodologies from the classifier, which would be valuable prima facie, as a way to understand how these attacks work, even if you are not the DOD. It is curious, for example, that the attack method mostly likely to be confused for anything else is FGSM.
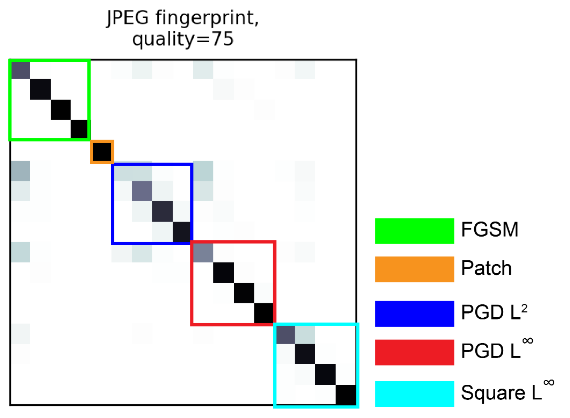
If you are in fact the DOD (hi!), it could be interesting to apply a more robust fingerprinting method to a dataset with a fine level of granularity in different attack methodologies -- i.e. not just the attack method and perturbation limit discussed in the paper, but also different datasets and models used to train the attack.
Is this interesting?
-
F. Tramèr, N. Carlini, W. Brendel, and A. Ma, “On Adaptive Attacks to Adversarial Example Defenses,” p. 13.
-
D. A. Nicholson and V. Emanuele, “Reverse engineering adversarial attacks with fingerprints from adversarial examples.” arXiv, Feb. 01, 2023. Available: http://arxiv.org/abs/2301.13869