For the last few months, we have been describing defenses against adversarial attacks on computer vision models. That is to say, if I have a model in production, and someone might feed it malicious inputs in order to trick it into generating bad predictions, what are defenses I can put in place around the model to help it perform better?
In adversarial training, we saw that you can feed a model adversarial inputs at training time, and that this both improves its robustness to adversarial attacks and makes the model features themselves more robust, and better aligned with human expectations. The downsides to this method are (a), that the model becomes much more expensive to train; (b), that the defense may be very dataset dependent; and (c), that the model may end up being robust to attacks, but has no way of letting you know that your model is under attack. This last point is important, as you may want to e.g. revoke the API key of someone attacking your model.
Next, in you need more JPEG, we saw that a second strategy is to perform a sanitizing or smoothing operation on inputs before they reach your model. The primary benefit is how cheap this is to implement, in terms of computational time. The downside is that this defense is easily bypassed, as later work showed, and that it can degrade model accuracy on normal images.
A third option is to detect an adversarial input before it ever reaches your model, and either refuse to provide a prediction for it, or feed it to an adversarially robust computer vision model (e.g. one that has been trained following the first defense tactic).
This is not an easy thing to do. Different kinds of attacks tend to perturb images in different ways, and a defense against one might not translate well to another.
In "Detection based defense against adversarial examples from the steganalysis point of view", the authors highlight a comment that Ian Goodfellow once made, that adversarial attacks can be seen as "hiding" unwanted information in an image.1 This is called steganography, and there is a large body of work about how to detect whether an image contains any of this kind of hidden information (steganalysis).
The authors describe an approach to detecting adversarially attacked input images by using two steganalysis methods.
First, they implement SPAM, which constructs pixel over pixel differences in eight directions: up and down, left and right, and the four diagonal directions. They then learn a transition probability based on these. So, for example, if I have three adjacent pixels, 154, 152, and 151, my differences are 2 and 1, and I want to learn the probability of seeing a difference of 1 given that my current pixel has a difference of 2.
In the integer representation of pixels, there are 255 distinct values that a pixel can take, and therefore 512 possible differences. This is a lot of transition probabilities to learn! So the authors bound the pixel differences to ±3. This works for classic adversarial attacks on images, since there is a strong incentive to minimize the magnitude of the pixel changes (to avoid obviously modified images that could, e.g., be detected by a human observer). In classic steganography, there is a similar incentive to avoid detection by making only very small changes, so this approach works in both domains.
The per-pixel change probabilities are averaged to reduce the dimensionality, but this still results in a total of 686 features.
The second method, SRM, is closely related to SPAM, but instead of modeling the transition probability, SRM tries to model predict the magnitude of the next change, then models the error in that prediction. To make this feasible, this model uses a set of kernel functions that expand beyond just 1D differences in adjacent pixels, but can instead incorporate information surrounding the pixel in all directions. This is a lot like a convolutional layer in a CNN, but instead of learning the right convolutions from the data, these are given in advance. Nonlinearities are added by taking the minimum and maximum of error probabilities across several filters.
The per-pixel error magnitudes are again limited to a restricted range, but this still results in a large number of input features -- 34,671 in total!
Now that we have some features that describe small but possibly unexpected pixel value changes in an image, we can use these as inputs to a model that learns a binary classification of normal v adversarial. To do this, you will need some training examples of adversarially perturbed images. The authors in this case use Fast Gradient Sign (FGSM), DeepFool, and Carlini-Wagner to generate examples of adversarial attacks on a subset of ImageNet.
Now the authors do something interesting here. In classic steganography, any pixel in the image is equally likely to be modified. In adversarial attacks, however, the pixels that get modified are likely to be those that are particularly useful in deciding what kind of an object is in that image, and will tend to cluster around that object as opposed to background locations.

So they use a set of adversarial attacks to estimate the likelihood that an individual pixel will be changed. For FGSM they use the gradient backpropagated to the input image pixels directly. For Carlini-Wagner and DeepFool, they do this by taking the delta between a clean image and an attacked one, normalize them, and use this as input to a pixel-importance model.
During the steganalysis step, the authors first generate this probability map using their known attack methods. Then, they weight each individual transition probability by the likelihood that it will be attacked. This, in theory, should help their detector ignore unimportant areas of each image and focus instead on areas important to the image classifier.
Finally, they feed these weighted probabilities into a Linear Discriminant Analysis (LDA) model, that is trained in a supervised fashion to learn to separate clean inputs from adversarial ones.
How well does this work in practice? Pretty well! Across the attacks that they try (on a pre-trained VGG-16 model), their staganlysis method averages about 95% accuracy in detecting attacked images.
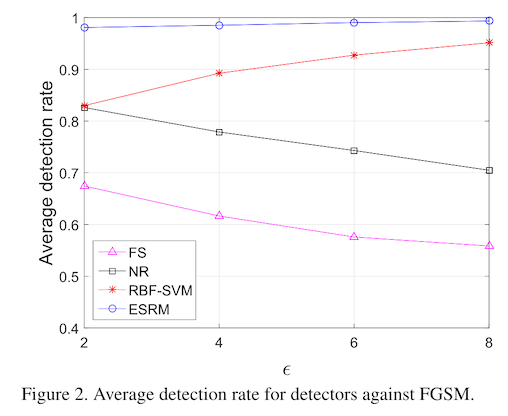
The probability-based pixel re-weighting helps a little bit but not a lot -- maybe just two or three percentage points in improvement. This might be a lot of work to do in practice, especially if this is a pre-detection step that is deployed in front of a standard object classification model. The pixel reweighting might end up taking more compute than the model it is protecting.
And, of course, this method assumes that the defender has some idea about which methods could be used to attack the model that they have deployed. It's hard to know this in advance, but we'll see next time that you might be able to figure out how an attacker is generating their adversarial inputs -- down to the specific code base.
Is this interesting?
-
J. Liu et al., “Detection Based Defense Against Adversarial Examples From the Steganalysis Point of View,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA: IEEE, Jun. 2019, pp. 4820–4829. doi: 10.1109/CVPR.2019.00496. ↩