In the papers that we have discussed about adversarial patches so far, the motivation has principally involved looking at the security or safety of machine learning models that have been deployed to production. So, these papers typically reference an explicit threat model where some adversary is trying to change the output of a model in a way that the user of that model would not want.
Some examples of this that we have seen already include:
- adding an adversarial patch to a t-shirt to bypass CCTV security cameras (Evading real-time detection with an adversarial t-shirt)
- adding an adversarial patch to your face to gain access to a system protected by facial recognition (Faceoff : using stickers to fool face ID)
- adding an adversarial patch to a traffic sign to cause autonomous vehicles to get into accidents (Adversarial patch attacks on self-driving cars)
But what if you have the opposite problem? Let's imagine a scenario where you are working on a robot that scoots around a warehouse and visually locates and identifies the items you have in storage. Computer vision systems are often sensitive to things like viewing angle and object orientation, so if e.g. one of the items is sideways, it might not be correctly recognized.
You can use the same methodology we have been describing for generating adversarial attacks and use them to boost the performance of computer vision models, instead of degrading them. In 2021, Salman et al. presented a paper investigating this usefulness of this strategy in a variety of settings.1 They call these "unadversarial examples".

They start with a set of in silico studies looking at image classification on ImageNet in the presence of perturbed images. First, the authors design a set of patches by taking a resnet-18 model, but instead of optimizing the negative of the model loss on the training data, they optimize the regular loss, giving them a patch that helps models have better accuracy.
Then, they look at the resnet-18's accuracy both on the image set with and without patches, under clean and perturbed conditions. The perturbations they apply include things like changing the brightness or contrast of the image, which are typical data augmentation strategies; and, things like JPEG compression and motion blur, which are not typically used as augmentations when training vision models.
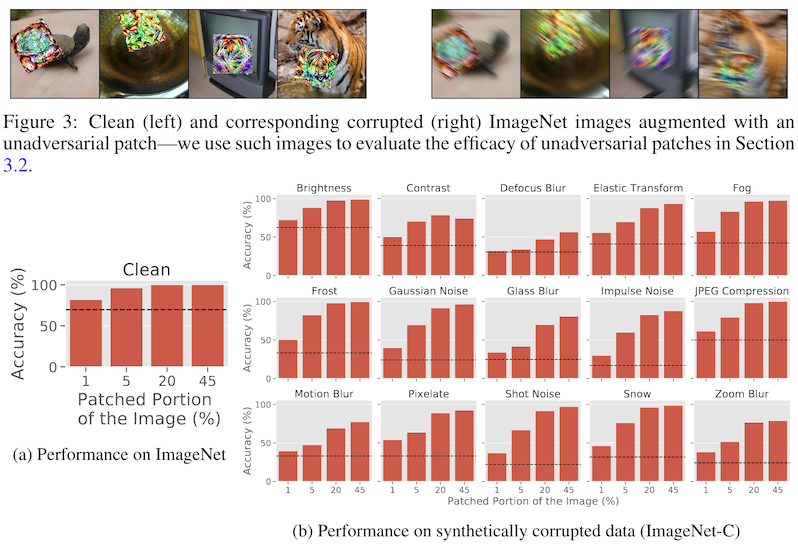
They find that, in all cases, the presence of the unadversarial patch helps the classifier maintain high accuracy, even in the presence of strong perturbations like blurring or zooming. In six of the ten cases where model accuracy started below 50%, adding the patch increased it above 75% -- a big difference!
Interested in adversarial patches? See more here!

The next experiment uses AirSim, an open source simulator for training autonomous vehicles.2 In this case, instead of training a fixed-size patch, the authors train a texture that can be used to cover the entire object. They do this by using a rendering engine to warp an adversarial patch over a 3d mesh of the object, then backpropagating the model loss (this time, a resnet-50) through a linear approximation of the original transformation, following Athalye 2017.3
First, they use this texture application process to generate adversarial patches for a plane, a bus, a truck, and a boat. They then recreate this objects in AirSim, and test the classifier under a variety of simulated weather conditions, like snow and fog. Again, the unadversarial patch helps the vision system be more robust to the inclement conditions.
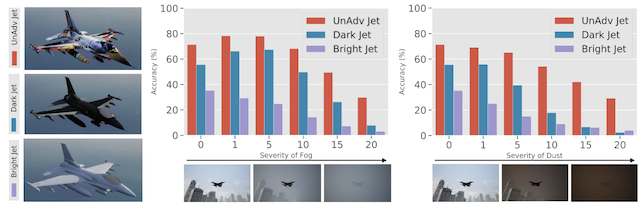
They repeat this process, but this time in vivo, by buying a toy plane and toy car from Amazon, and applying patches to the physical objects using a printer and some tape. They do not put the toys in any inclement weather, but do take pictures from varying angles and note that the patches help the model maintain good accuracy across all of the object orientations.

But what about the implications of these results? In our example at the start of the paper we mentioned identifying items in a warehouse, but there are other (sometimes safety critical) applications where an autonomous system is using vision, because that environment was originally designed for human operation.
You could, for example, make an unadversarial stop sign, to increase the likelihood that autonomous vehicles will stop when they are meant to. Maybe you wear an unadversarial t-shirt to make sure that you look like a human when you are in a crosswalk, no matter your body's orientation with respect to the cameras on the vehicle.
Was this interesting? Sign up for our email list!
-
H. Salman, S. Vemprala, A. Ilyas, A. Ma, L. Engstrom, and A. Kapoor, “Unadversarial Examples: Designing Objects for Robust Vision,” p. 15.
-
https://github.com/microsoft/AirSim
-
A. Athalye, L. Engstrom, A. Ilyas, and K. Kwok, “Synthesizing Robust Adversarial Examples,” arXiv:1707.07397 [cs], Jul. 2017. [Online]. Available: http://arxiv.org/abs/1707.07397