We've spent the last few months talking about data poisoning attacks, mostly because they are really cool. If you missed these, you should check out Smiling is all you need : fooling identity recognition by having emotions, which was the most popular post in that series.1
There are two more kinds of adversarial patch attacks that we didn't cover earlier, so we're going to hop back and take a look at those now. The first thing we'll talk about is inference-time attacks on identity recognition.
Now, we've already seen two data poisoning attacks on identity recognition that make use of a technique called adversarial watermarking. The idea here is that you, the attacker, have some control over a small fraction of the training data used to train an identity recognition model. This could be because you upload them to a service (e.g. like Facebook) or you are putting them on the public internet with clear labels (e.g. uploading photographs of a celebrity to Wikimedia). You apply a watermark to the images of a specific person, where that watermark might be a typical image watermark or it might be an attribute of the person, like wearing a specific pair of sunglasses (or a smile!). Models trained on that data can then be "backdoored" later by applying that same watermark to other random stuff and causing it to be misclassified as the thing you were watermarking in the training data.
Is this interesting?
This was cool because it was relatively easy to do and hard to detect. But what happens if you don't control any of the training data? E.g. if you are trying to sneak into a secure building that uses facial recognition, odds are the security company isn't using your personal Facebook photos or images from Wikimedia Commons. So what can you do?
Use an adversarial patch!
Here is a quick refresher about adversarial patches: we want to use an adversarial attack, but by modifying the world, not by modifying the digital representation of an image. This means there is a process that we don't control (someone or something takes a photo or a video) between us and the model we want to attack. Because of this, our attack can't be those imperceptible changes you typically see in papers on adversarial machine learning because being imperceptible means the camera won't record it!

So what we do instead is we change a small area of the image a whole lot. Typically this means we occlude an object by priting an adversarial attack directly onto it, or we print something on a sticker and then slap the sticker onto the object. For more, you can see our post on the original adversarial sticker paper here: fooling AI in real life with adversarial patches.
Okay, back to facial recognition: the paper that kicked this off was the fake glasses paper titled "Accessorize to a crime"2 (great legal pun btw) where a team of researchers printed out an adversarial patch in the shape of a glasses frame. You may have seen this image in particular

in news articles from The Verge, Vice, Quartz, or The Guardian in 2016.
The basic strategy here is to take an off-the-shelf face recognition model (like VGG-face or ArcFace) and then transfer it to a dataset that includes your test subjects by replacing the last fully-connected layer of the neural network and retraining it on your own data. Then, you train an adversarial patch on that surrogate model in the white-box setting and hope that it works on other identity recognition models too.
The goal of the attack is one of two things: either, stop looking like yourself (the authors call this a dodging attack, but these days people typically call this an evasion attack); or, look like one, specific, other person (the authors call this an impersonation attack).
Like all pioneers, the authors are themselves the test subjects in this paper, and they throw in different amounts of not-themselves data. In one iteration this is five other people, which is... very small. A later iteration trains a model to recognize 143 other people, which feels more ecologically valid (e.g. a business with only 10 people probably does not need facial recognition software to tell which employee is which).
A couple of interesting things to note about this paper.
First, the authors decide specificaly to use "geeky glasses" as the patch shape -- this is a direct quote from the paper:
Unless otherwise mentioned, in our experiments we use the eyeglass frames depicted in Fig. 1. These have a similar design to frames called “geek” frames in the eyewear industry.

I don't know that those are widely known as geek glasses -- they look like Rayban Wayfarers to me? Are Wayfarers only for geeks? Anywho --
Second, the attacks are less successful for subject C (SC), who is someone who already wears glasses. We saw this in one of the data poisoning papers too, and the researchers there got around it by using sunglasses instead, as these were less likely to show up in the training data.
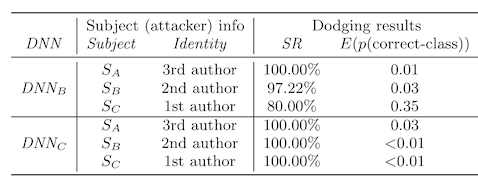
Third, it's harder to conduct an impersonation attack between genders or ethnicities. This might feel obvious to you, but bear in mind that computer vision algorithms don't have ontological categories and are just as likely to use your face to identify you as they are to use anything in the background that isn't actually related to you at all (e.g. see "When reality is your adversary"). Specifically, in this paper, we see subject B struggle to convince a model that she is Colin Powell, and there are two cross-ethnicity comparisons that also have low success.
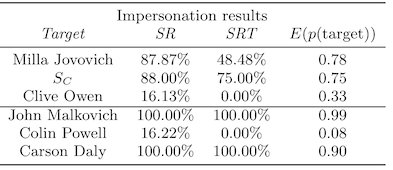
There are a couple of issues with this analysis. First, the images are all pre-aligned and corrected, which makes face recognition a relatively easy task for the machine learning model. Bear in mind that the FBI's original face recognition algo involved applying PCA to pre-aligned, cropped, and corrected photographs of faces (like passport or drivers license photos). Second, given the small size of their training data and what we know in hindsight about inference time attacks, the reported attack success rates seem a bit high.
So, a few years later, a team at Huawei Moscow repeats this study in a paper called "Real world attack on ArcFace-100 face recognition system".3 They use a more modern pipeline (MTCNN) that includes face detection followed by extraction and then identification. They also use a slightly larger amount of identities (200 other people) in their transfer learning process.
The first result is that they can't get the glasses to work without making them comically large:

The second result is that they notice their stickers, unlike the Sharif et al. paper, have realistic-looking objects on them. E.g. Their forehead-sticker adversarial patch has realistic facsimiles of eyebrows on it:

The third result they note is that their attack success rate is largely dependent on two things:
- the size of the sticker; and,
- how close it is to the eyes.
So, for example, moving the forehead sticker progressively lower improves the attack success (but presumably also interferes with vision if it gets low enough). This was noted in the "Accessorize to a crime" as well, in the form of an accessory experiment that looked at where a traditional, digital adversarial attack would modify pixels the most in front of a face, and it ends up being right at they eye-nose-eye junction:

Unfortunately, the authors don't report the attack success rate (ASR), which is the standard metric for evaluating adversarial attacks. Instead, they report cosine similarity of the final model embedding layer, which may or may not translate into real life model confidence as expected.
The same research group followed up that same year with "AdvHat : real world adversarial attack on the ArcFace Face ID System", where they repeat the experiment with the forehead patches but this time with adversarial patches that have color4
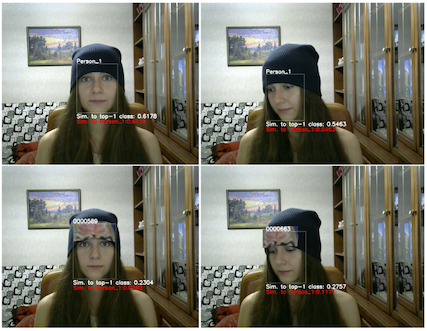
And this time, with 1000 other classes in the training set! This seems to lead to an improvement in their similarity metric, but again -- it's not clear how this translates to ASR.
But! It's an intriguing idea that you can copy someone's forehead (with eyebrows), stick it on a beanie, and appear to be someone else. Anyways it's way easier than that Mission Impossible face mask thing.
Or getting someone else's face surgically exchanged for your own 😬
-
It definitely had the most click-bait-y title, which seems to work well as an adversarial attack on human attention 🙃
-
M. Sharif, S. Bhagavatula, L. Bauer, and M. K. Reiter, “Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition,” 2016, pp. 1528–1540. doi: 10.1145/2976749.2978392.
-
M. Pautov, G. Melnikov, E. Kaziakhmedov, K. Kireev, and A. Petiushko, “On adversarial patches: real-world attack on ArcFace-100 face recognition system,” arXiv:1910.07067
-
S. Komkov and A. Petiushko, “AdvHat: Real-world adversarial attack on ArcFace Face ID system,” arXiv:1908.08705