In the last post, we talked about one potential security risk created by adversarial machine learning, which was related to identity recognition. We saw that you could use an adversarial patch to trick a face recognition system into thinking that you are not yourself, or that you are someone else specific.
The former case is called an untargeted or evasion attack, because the effect of the patch is to reduce the likelihood of being identified by the algorithm. The latter case is called a targeted attack, because the goal is to be classified with high confidence, but for a specific identity that you are not.
This misidentification risk extends to any domain where identities are established visually. Like driving.
When you drive a car, you visually identify lane boundaries, intersections, stop lights, traffic control signs, etc. This works pretty well most of the time because :
- traffic signage tends to be large and high contrast; and,
- sign designs are simple and have redundant distinguishing features (e.g. color and shape); and,
- the human visual system is robust to lots of perturbations.
For example, this image

is clearly recognizable as a stop sign to a human, even though a large portion of it has been covered in paint. We can still see the word STOP, can still see that it's octagonal, and still see that the sign is (mostly) red.
But what would a computer make of this?
We've already seen that computer vision models tend to not use the same features that humans do when classifying images (see "When reality is your adversary : failure modes of image recognition"). In particular, they pay a lot of attention to texture, and less attention to shape, and obviously do not speak English, so that bit of graffiti on the sign might change the texture on the sign enough to cause problems for a computer vision model.
Here's another example of a stop sign

that is still recognizable as such to a human, but gets misclassified by a traffic sign recognition model as a speed limit sign with 80% confidence.
How did this happen? That stop sign is actually a fake one, printed out by a research team, with an adversarial pattern added to the bottom half. Note the dark -> light -> dark texture there? If you squint really really really hard, that texture looks a bit like the bottom half of this sign:

It turns out that pattern works on existing stop signs too, if you mark out the dark and light parts with black and white electrical tape like so

Wild, right? These images come from "Robust physical world attacks on deep learning visual classification", a collaboration between Samsung, Stony Brook, Cal, U Mich and UW.1 The authors were particularly interested in the risks and failure modes associated with self-driving cars, and wanted to see how hard it would be to fool two computer vision models -- LISA-CNN and GTRSB-CNN -- that were developed specifically for the classification of images of traffic signs, in a white box setting.
The bad news (if you make cars) is that this turned out to be pretty easy. The first set of experiments involved printing out an entirely new stop sign, where the adversarial attack was allowed to alter any portion of the sign that helped it get misclassified as a speed limit sign. In their experiments, the attack success rate (ASR) of this approach was close to 100%, so they decided to make the task a little bit harder, and restrict themselves to modifying just a small part of the sign.

They way that they did this was particularly clever. They trained a two step attack -- the first attack used an l1 loss to select which parts of the sign had the highest sensitivity to perturbations. Then they trained a second attack targeting just those blocks of pixels with an l2 loss on the pixel values. This reduced the ASR down around to the 80% range.
The good news (if you make cars) is that these were very simple convolutional models, and the task used to train these models was classification. Neither of these is likely to be true of computer vision models that get deployed into self-driving cars. And, because object detectors are known to be harder to attack than image recognition models, the ASR is also likely to be lower.
In a follow-up paper, "Physical adversarial examples for object detectors", the authors repeat their approach but this time against an object detection model -- YOLOv2 -- in a white box setting.2

The authors again take two separate attack methods: printing an entire fake stop sign, and placing stickers on a small portion of a stop sign. This time the stickers also get printed (e.g. they are not just black and white), and instead of determining their size and position directly from the loss, they are fixed rectangles above and below the word STOP.
The attack success rate is notably lower -- the whole-stop-sign attack goes from an ASR of 100% against the image classification models to 72% against the object detector. Similarly, the sticker attack drops from the 80% range down to the 60% range.
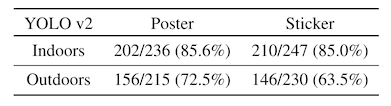
To be sure, 60% is still too high of a failure rate for e.g. a self-driving car recognizing a stop sign, but that 60% number may also be a bit optimistic. In the first paper, the authors have a quite robust testing framework, where they stick a camera onto a car and drive up to an attacked stop sign while recording video.
In the second paper, the testing appears to be less rigorous. The authors are light on the details of how they evaluated these patches in the methods section, but the associated figure appears to show photographs of one experimenter holding the sign while another experimenter takes a short video while walking toward them.

Finally, the authors close with an attempt at making an adversarial patch for stop signs, like the adversarial toaster sticker. They characterize a potential attack vector as being like a denial of service (DOS) attack -- with enough stop sign stickers, you could cause a car to think it is surrounded by stop signs on all sides.

The authors note
we have spent considerably less time optimizing these attacks compared to the disappearance attacks—it is thus likely that they can be further improved

More about how to make these kinds of t-shirts in a future blog post!
Is this interesting?
-
K. Eykholt et al., “Robust Physical-World Attacks on Deep Learning Models,” arXiv:1707.08945 [cs], Jul. 2017.
-
K. Eykholt et al., “Physical Adversarial Examples for Object Detectors.” arXiv:1807.07769 [cs], Oct. 05, 2018.