We've been reading through a lot of papers recently about defenses against adversarial attacks on computer vision models. We've got two more to go!
[For now anyway. The pace of machine learning research these days is dizzying]
Here's how wild the pace of #MachineLearning research is these days: a completely true story
— DillonGPT (@dillonniederhut) April 11, 2023
👇
In Minority reports for certifiable defenses we saw that you could take a small-ish binary mask, slide it across an input image, generate a set of predictions, and us the characteristics of the resulting set of predictions to generate a certifiably robust image classification label. But what if you aren't doing image classification?
To be more specific, that particular method had two weaknesses. First, it assumed that the size of the attack was known in advance (we'll get to that in a bit). Second, it assumed that you were only receiving images that had a single thing in frame -- only one dog, only one stop sign, etc. This assumption places pretty strong limitations on what kind of systems can be made robust against attacks. A camera on a self-driving car, for example, might see a dog and a stop sign at the same time.
Both of the solutions we'll look at today come from the same team at Princeton, but we'll start with DetectorGuard since that came first.1 In this paper, Xiang and Mittal find a clever way to re-use the previous work that had been done making classifiers more robust, by re-using the classifier itself.
Here's the basic setup: you start with an image, and you want your model to detect any object in the image by drawing a rectangle around where it is, and giving you a label to say what kind of thing it is. Here's an example of what that looks like:

So you start by doing the normal thing -- you give the image to a regular object detector like YOLO or FasterRCNN, and get an output that looks like the image above. But, if someone adds an adversarial patch to the image, you object detector won't work properly:

So you take the same input image, and give it to a robust image classifier. The one that Xiang and Mittal use is a bit different than the ones we talked about in the last post. Instead of sliding a classifier across an image and getting a set of predictions for each location, they use a method (Clipped BagNet) that only does a single forward pass, but still gets localized predictions.
Briefly, the way this works is that the model has small convolution sizes, and these sizes do not get larger as the model gets deeper (which is usually how they are designed). This keeps the model from aggregating visual information across the image during the feature generation step, and semantically is similar to only propagating localized information all the way down to the final layer of the model. Because the fields are small, you would expect each of them to have relatively little signal individually, so any localized feature that looks like it has a lot of information is relatively suspect. You can ignore those suspicious fields (which might be an adversarial patch!) and base your decision on the rest of them.
Now, we're not interested in having a single label for the whole image, so what Xiang and Mittal do is look at how confident the model is about its classification at each receptive field. If that confidence is over a certain threshold, they then say, we don't care what the label is, but this must be an object of some kind. They call this objectness.
Finally, we can put these two predictions together.

- If the vanilla object detector gives us a box, and the robust classifier fills that box with objectness pixels, then we can be assured that the object detector made a good call.
- If the object detector gives us a box, and the robust classifier gives us no objectness pixels at all, then we assume the classifier is wrong and keep the object detector result.
- But! If the object detector gives us no box, and there are lots of objectness pixels clustered together, this is an indication that there is some unexplained object in the image and we might have a model under attack.
There are two nice things about this approach. First, because you can run the object detector and the robust classifier in parallel, and because the object detector is usually the rate-limiting step anyway, the runtime overhead of this defense is essentially nothing. Second, it relies on a large body of work in certifiably robust image classification, so the methodology is well-attested.
The accuracy, however, is not great. The authors are measuring this with something called recall, which is the probability that the model will find an object in the image if one is actually there. In situations where a model would have close to 100% recall on clean images, the recall on attacked images can be as low at 6%.
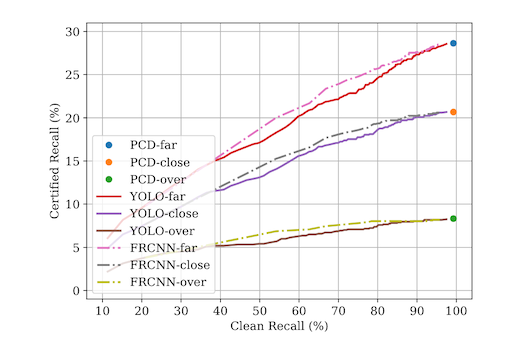
So, what we want is an approach that gets better recall on attacked images like Minority Reports did, but that works on object detectors. What the Princeton team does is adopt the masking approach, but designs the masks a little better.
Recall2 in the earlier masking works, a square (or rectangle) was slid across the input image, then up and down the input image. Wherever that square was, we zeroed out all the pixel values and fed that image to the model to get a prediction. Then, we aggregated a final, single prediction, from the prediction set.
In ObjectSeeker, Xiang et al. only use rectangles that are at least as big as the input image in one dimension.3 And, instead of sliding a single rectangle across the image, they accumulate them from left to right, right to left, top to bottom, and bottom to top. It's a lot easier to see what this looks like as a picture than for me to describe it in words:
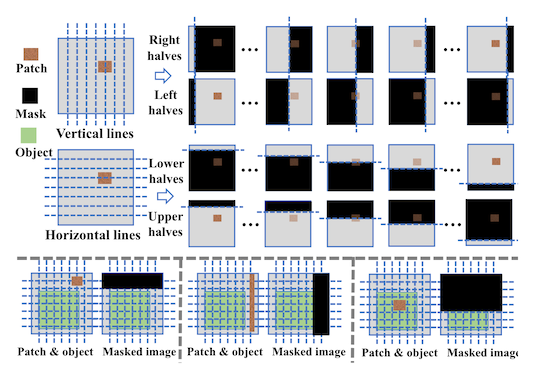
In the extreme case, you might only have 5% of the image left to give to the model! But this is okay, because it means that some of the inputs are guaranteed to not have a patch in them, as long as that patch is rectangular and not the same size as the input image itself.
You give each of these to an object detector, and still get a prediction set, but this time the prediction set will be a collection of boxes instead of a collection of labels. So your next problem is figuring out which boxes are the right ones to keep!
There is a two step approach to this, and the way it works depends on whether your image is clean or attacked. In both cases, you give the image to an undefended object detector and the masking-detector at the same time. If your image is not attacked, the vanilla object detector will have the right boxes, so you go one by one through the masked box collection, and throw out anything that overlaps with a box from the first model.

If there is an adversarial patch in the image, the undefended model won't produce a box. So, when you go to delete any boxes from the masking-detector, they will all still be there. In the attacked case then, there is a second step where you cluster the remaining boxes based on location and take the union over individual clusters.

The end result of all this is a certified recall against attacked images that about 3x better, for worst-case images, than the previous paper. Not bad!
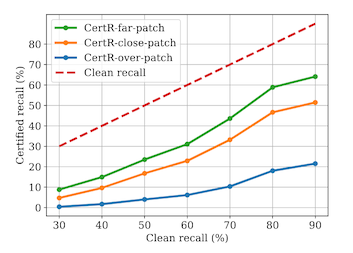
There are four things to end with here.
First, 20% recall is still far below what would be useful in practice, if you are imagining e.g. an autonomous vehicle trying not to hit pedestrians but only seeing 1 out of 5 of them.
Second, the authors have split out their recall measurements into patch location -- whether it is nowhere near any objects, next to an object, or directly on top of an object. The location directly on top of the object is the one most likely to be deployed in real life, and is also the worst case scenario for this defense!
Third, the authors note that this defense will fail completely if an adversarial patch somehow was able to cover an entire object. We'll follow up on this point specifically in another blog post or two.
Fourth and finally, you may have noticed something a little weird about our discussion of these defenses. In particular, we said in both papers that an adversarial patch could only ever cause a model to fail to detect an object. The authors are very clear that these defenses are only designed to handle evasion attacks, and would not be effective against misclassification attacks like traffic sign stickers, which do represent a real attack vector.
But maybe the Princeton team is working on that already!
Is this interesting?
-
C. Xiang and P. Mittal, "DetectorGuard: Provably Securing Object Detectors against Localized Patch Hiding Attacks." arXiv, Oct. 26, 2021. Available: https://arxiv.org/abs/2102.02956
-
See what I did there?
-
C. Xiang, A. Valtchanov, S. Mahloujifar, and P. Mittal, "ObjectSeeker: Certifiably Robust Object Detection against Patch Hiding Attacks via Patch-agnostic Masking." arXiv, Dec. 28, 2022. Available: https://arxiv.org/abs/2202.01811