In the recent series of blog posts about making computer vision models robust to the presence of adversarial attacks, we have mostly been looking at the classic notion of an adversarial attack on an image model. That is to say, you the attacker are providing a digital image that you have tweaked to cause a model to misclassify what is located in that image. You can change any pixel you, by however much you want, although typically you try to keep each change small, to make it harder for anyone else to notice what you have done.
But we have already seen (e.g. in Fooling AI in real life with adversarial patches) that this isn't always a realistic threat model. In particular, it assumes that you will be uploading a digital image to someone else's model -- maybe, for example, you are posting a photograph of yourself to Facebook. But what if your friend takes the photo? And posts it to Facebook and tags you?
To get around this, we need an adversarial attack that can be deployed in the lived environment, like printing an adversarial patch on a t-shirt. In theory, if the attack is effective enough, this would prevent you from being detected in Facebook photos or by CCTV cameras.
The defenses we have seen so far might not apply well to these adversarial patch attacks. In particular, they tend to rely on image compression or denoising, which works well for small perturbations distributed across a wide area but may be less effective on a very large perturbation, like an image printed on a t-shirt. JPEG compression, for example, doesn't remove adversarial patches from images.
To address the need to keep computer vision models safe in the presence of adversarial patch attacks, you need to somehow de-patch-ify the input images to the model. If you knew where the patch was, you could replace the attacked pixels with a block of 0 values and (hopefully) recover something close to clean model accuracy.
But you won't know where the patch will be.

So instead what you can do is take a block of blank pixel values, and slide it across the input image in both the x and y directions. If your block of blank pixels (a mask) is larger than patch being used to attack the image, you can be guaranteed that at least one of the masked images will get the right classification (or, at least, not the classification the attacker wants).

But this leads to a weird situation. Instead of a single prediction, you now have a set of them, and they might not all agree. How do you know if this is a problem?
Enter "Minority Reports Defense: defending against adversarial patches".1 In this paper, McCoyd et al. propose an algorithmic solution to using the distribution of disagreeing predictions to decide whether an input is adversarial or not.
The algorithm works like this: you start by taking a mask and sliding it across each input image, generating a series of partly-occluded inputs for each original image. These get fed to the model, and each partly-occluded images gets some class label that represents what is in that image, along with a confidence in the prediction (these are just logit probabilities from the model, not calibrated confidence scores). Record the majority prediction, and go on to step 2.
In step 2, you make a grid of all the predictions, where the predicted label and confidence map to wherever the mask was placed on the original input image. Slide a 3x3 window over that image, and at every step, look at the majority class prediction only in that window and the associated confidence. Any given window is internally in agreement if the average confidence in any class is 90% or greater. This gives you a grid of votes for each 3x3 window.

In step 3, you look at that voting grid. You ignore any window that was not internally consistent. Of the remaining votes, if there are any that vote against the original majority prediction from step 1, this means that your model has been given an adversarial image.
Why does this work? If your mask is large enough, there will be at least one mask that covers the patch entirely, and recovers (hopefully!) the correct prediction. If you slide that mask a little to the left or to the right, it will still be mostly covering the patch, and is likely to recover the correct prediction. A spatial cluster of disagreement with the majority vote from step 1 indicates that there is something local to that place in the image that causes the model to predict something very different when it is removed. That something could be an attack.
It could also just be something else in the picture! Like maybe someone took a photo of a dog, but there is a cat in the foreground. This work was conducted on the image datasets MNIST and CIFAR-10, which are curated specifically to not have more than one object in the image, so that situation didn't show up during training. But, this might not translate well to real life deployment scenarios. In addition, we never try to recover the true label -- this method just detects if an image is likely to have been tampered with.
A couple years after Minority Report was published, a team of researchers at Princeton tried to address that second part -- is it possible to recover the true label?
Surprisingly, you can do a pretty good job of getting the true label from the adversarial input. And this is going to sound a bit silly, but you do this by... taking a second minority report.
The way this works is detailed in "PatchCleanser: certifiably robust defense against adversarial patches for any image classifier".2 The first step is the same -- you take a mask, slide it across the image, and get votes from each of the partially occluded images about what the model thinks is there. If there is a minority report in the first round, you might have an image containing an adversarial patch.
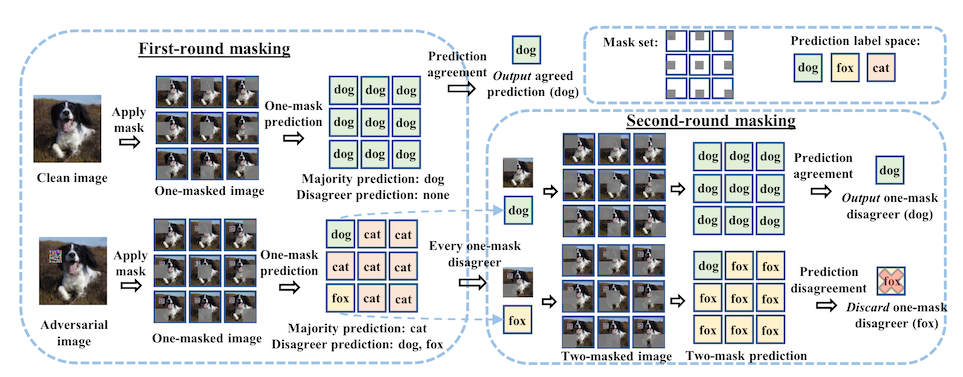
Then, you take every occluded image that disagreed with the majority vote and apply a second set of masks. If there is a minority report in the second round, something weird is happening. Maybe there are two patch attacks in the image! Maybe it's just a weird photo. The authors recommend defaulting back to the majority vote and getting on with your life.
But! If there is no minority report in the second round, this means that your image has been attacked, and the minority report is the correct one. The accuracy of the approach is better than I would have guessed -- almost no degradation on clean images, and a certified robust accuracy that beats previous work by a factor of 2.
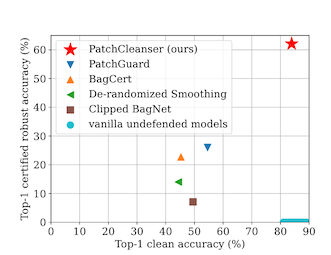
Now to be clear, dropping from 90% accuracy to 60% accuracy is still a big drop, but 60% is also better than 30%.
But why does this work? Well, if one of the masks from step 1 is covering a patch, then it is likely to issue a minority report. And, if that mask covers the whole patch, then adding a second mask is unlikely to cause a second minority report.
On the other hand, if there is a minority report in step 1 over something benign, there will be a second mask which covers the patch, generating a second minority report, and indicating that we don't want to use the first minority report for our ultimate model prediction.
And if there is no attack in the image at all, it is unlikely that you will get that first minority report in the first place.
We still don't, however, have any good way to deal with two objects in the same image though. We'll talk about that in the next blog post.
Is this interesting?
-
M. McCoyd et al., “Minority Reports Defense: Defending Against Adversarial Patches.” arXiv, Apr. 28, 2020. Available: http://arxiv.org/abs/2004.13799
-
C. Xiang, S. Mahloujifar, and P. Mittal, “PatchCleanser: Certifiably Robust Defense against Adversarial Patches for Any Image Classifier.” arXiv, Apr. 08, 2022. Available: http://arxiv.org/abs/2108.09135