The last three papers that we've read, backdoor attacks, wear sunglasses, and smile more, all used some variety of an image watermark in order to control the behavior of a model. These authors showed us that you could take some pattern (like a funky pair of sunglasses), and overlay it on some pictures of the same thing (say, a toaster), and then put those images in a place where an unlucky machine learning engineer might find them. If your watermarked images get used to train a model, you can make that model incorrectly predict that there is a toaster in an image by applying that same watermark. Viz. if you put on the funky sunglasses in real life, you become a toaster in that model's eyes!
It's pretty shocking how successful these kinds of attacks were -- it was possible to fool identity recognition algorithms by selectively poisoning the training data with natural facial movements like smiling or opening your mouth. Furthermore, these attacks were successful with very small amounts of poisoned data -- you could make a few hundred of these watermarked images and gain control of someone else's production model. This has obvious security implications, especially where facial photographs are used for authentication.
But most of us aren't going around trying to convince a computer vision system that we're a particularly famous celebrity, or a toaster. It's more likely that we enjoy having image classification algorithms that can auto-categorize the pictures we have on our phones, and let us search for the ones with dogs, or the ones we took in front of a statue. We are, however, worried about privacy.
The rise of social media has made it easier to stay connected with friends and family, but it also means putting a lot of personal information (like photographs of ourselves) on computers that we don't own. Companies like Clearview might be using these photographs in ways that we didn't agree to, or find morally objectionable. We can always ask that they stop, but short of a lawsuit, we're really taking their word for it when they say they haven't / won't anymore.
But what if there was a way to tell -- just from the model -- whether it's been trained on our data?
In Radioactive Data: Tracing through training, Sablayrolles and their co-authors wanted to know the same thing -- is it possible to detect whether a model was trained on a set of images? You can, but it takes a bit of work.
First, you need to have access to two things:
- the model under test -- at the very least, you need to be able to give it some inputs, and receive a prediction and associated confidence in that prediction; and,
- a surrogate model, preferably similar to the one you want to test, and the compute resources / know-how to train it from scratch
Second, we need a watermark. The watermark needs to be useful to the model or it will get totally ignored, so it needs to be aligned with class labels. This means that if you want to query an image classification model, you need a different watermark for each kind of image (one for dogs, one for celebrities, one for toasters, etc.). The watermark also needs to be hard to detect, especially by automated data cleaning methods. A traditional watermark -- like we saw in the previous papers -- is identical across images, which might make it too easy to spot. Here the authors do something clever but a little risky: they put the watermark in the feature space, not the pixel space.
What does this mean? When you give an image to a machine learning model, the first thing it does is convert that image into an intermediate representation which is more useful to work with. Your eyes do a similar thing -- they start by recognizing small patterns like lines, corners, circles, and gradients; then, they combine these patterns into complex features, like rectangles that are brighter on top than on the bottom; these get combined with other complex features to help you recognize the difference between a window and a laptop. The authors put their watermark in those complex features -- rectangles that are brighter on top -- and then translate them backwards into the pixel space, where it looks different in every image (they might not all have rectangles!).
Why is this risky? There's no a priori guarantee that different model architectures will resolve a group of images to the same intermediate representation. To go back to our biological analogy, the high-level features that flies pay attention to are not the same as the high-level features that you pay attention to! However, it seems to be generally true of both eyes and image models that anything designed to understand natural images tends to converge to a similar -- even if not identical -- set of intermediate representations. Corners are useful to spot whether you fly or you walk!
The authors check empirically that this works for their data watermarking attack. They train their watermarks on resnet-16, then evaluate the data poisons on resnet-50, densenet-121, and vgg-16. The performance is a little worse compared to evaluating on resnet-16, but is still usable in real life.
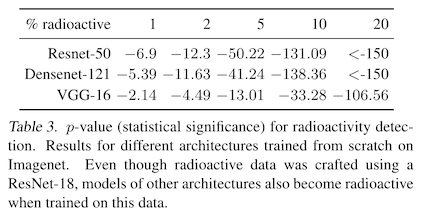
But we're getting a little ahead of ourselves -- how are these watermarks created? First, you need to take your surrogate model (a resnet-16 in this paper, which is a popular convolutional neural network used for image classification) and train it on a clean dataset (in this case, imagenet). Then, you use this to train your watermarks.
Training a watermark involves starting with: an image whose pixel values are all 0, and is the same size and shape as the dataset images; and a vector of random numbers -- one per image class -- the same size as the intermediate representation of the image that the model creates. Then, you push this image forward through the network, but stop after you have your intermediate representations and before the part of the model that uses those representations to decide what the image contains. Then you add your vector of random numbers to the feature space, and push it backward through the network to get the corresponding pixel changes in the original image. You don't want these changes to be large and noticeable, so you set a maximum amount each color value is allowed to change, and move the pixels a small step in that direction. You iterate over this procedure a few times, using a penalty term for the smallness of the change in the original image, and the closeness of the change in feature space to the random vector for that image class. Then voila! You have your watermark for that image.
To make sure this works, you then re-train your surrogate model from scratch, but with some percentage of images with watermarks -- poisoned images. The authors search over percentages of poisoned images in their study, and like prior work find that a higher percentage of watermarked images means it is easier to detect a poisoned model, but also that the model accuracy itself is more likely to suffer. To state this another way, the more of your watermarked data a model uses, the eaiser it is to tell that it was trained on your data. Intuitive!
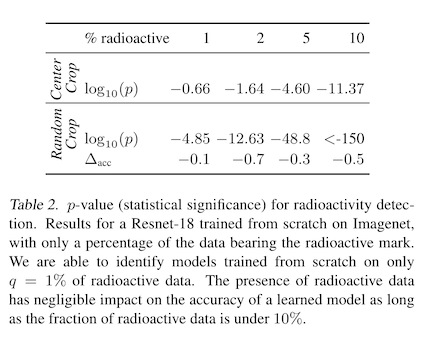
But also, the model may come to rely on your watermark more and more to tell images apart, so the overall accuracy of the model will suffer. This makes it more likely that someone will notice something has gone wrong, and try to discover what is wrong with the data that the model is trained on. Rememeber, we're trying to be stealthy!
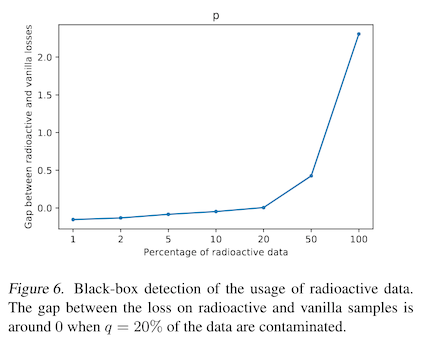
So what do these things look like? A lot like the adversarial perturbations we saw in What is adversarial machine learning. In fact, the authors note that this training procedure is similar to training an adversarial attack. The additive watermark is hard for human eyes to see, and basically looks like multicolored noise. But when applied to the training data, they become a useful signal to the model, which uses a lot of the same intermediate representations that your eyes do, but doesn't have the context to understand which of those features are useful and which were put there by ML researchers!

After an image recognition model has been trained on these watermarked images, you can give it two copies of a new image -- one watermarked, and one not. If the classification confidence is higher on the watermarked version, this is a signal to you that the model was trained on your poisoned data! We won't get into the details of this here, but the authors also derive a hypothesis test based on the chi-squared distribution that assigns a p-value to the magnitude of the confidence change. They find that with just 1% of training data watermarked, they can tell with high confidence that their watermarked data was used to train the model.
Of course, if you are interested in establishing whether an identity recognition model has been trained on your LinkedIn profile photos, it is unlikely that those will comprise anywhere close to 1% of the training data. There are a lot of people in the US! An interesting future direction here would be to see what changes you could make to the watermark generation step to allow smaller fractions of poisoned training data -- say, 0.001% -- and still be able to detect if those images were used.
Was this interesting?
-
A. Sablayrolles, M. Douze, C. Schmid, and H. Jégou, “Radioactive data: tracing through training,” arXiv:2002.00937 [cs, stat], Feb. 2020. Available: http://arxiv.org/abs/2002.00937